i built this thing that helps me discover new music and maybe you’ll like it too! bsky-bc. this is already a bad name because i plan to add Ampwall support soon.
this annoys me but i’m gonna leave it for now so i can eventually write an “x is now y” post and also I have bsky-bc hardcoded in a bunch of places and i don’t want to stop writing this post to go fix it, sorry!!!
aside: i want more bands and musicians to use text-oriented social media. i reluctantly got back on instagram recently because that’s where the bands (and tattoo artists) are, but i really don’t like being on there. shoutout Chat Pile for being a real poster.
anyway i’m having a lot of fun on bluesky in general, but i really love an open firehose of posts to build on again.
there are some good feeds aggregating bandcamp links: Skramz/Hardcord/Crust BC, Bandcamp Links, and Metal Bandcamp are the ones I have pinned. made me want to look into building my own feed generator, so i forked feed-generator and saw these lines subscription.ts:
// This logs the text of every post off the firehose.
// Just for fun :)
// Delete before actually using
for (const post of ops.posts.creates) {
console.log(post.record.text)
}sorry, comment: I deleted all the other lines and kept this line and filtered for posts containing bandcamp links, spit those out to the console as jsonl. figured that would let me tee the file so I could replay the stream later. this has worked out great.
once i got that first posts.jsonl file i got distracted from the feed generator and started playing with it to do other stuff.
browsers are rad
🏆 mvps 🏆
- if you simply don’t do anything it’s responsive out of the box
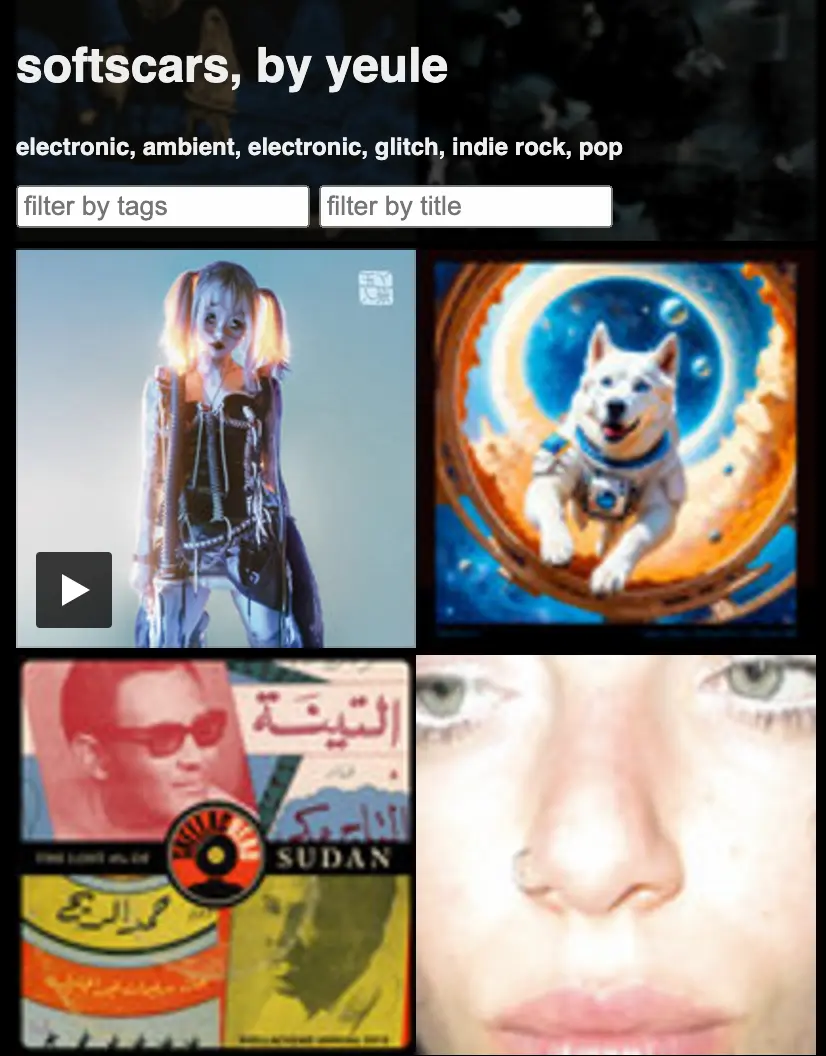
- threw a bunch of images right up next to each other and it worked great1
- easy when the “design” is just a big grid of images, but in general it’s rad that the browser is just designed this way by default.
- threw a bunch of images right up next to each other and it worked great1
<img loading=lazy>- important enough i would have implemented this if i had to, but i didn’t have to!
- between intentionally using low-res album art and using
loading=lazyi get solid performance on slow 4G.- ultimately this is for streaming music, figure slow 4G is a good enough lower bound
<datalist>- autocomplete without js!2
- don’t love calculating & debugging element positioning so if this wasn’t here i probably wouldn’t have had suggested completions at all, or at least not in the first version
- suppose i could use a strict dropdown but i want to be able to type “metal” and get all the metals
[attribute*=selector]- filtering creates
:not([data-tags*=search-term])style to hide everything that doesn’t match.
- filtering creates
firehose too powerful
i could rent a VPS but i’ve got this perfectly good NAS sitting here mostly idle, why not put it to work? i tossed the script on there and ran it in tmux. at this point, all it did was generate posts.jsonl. i would scp that down and run the rest of the pipeline to generate the page:
- filter to those containing album or track urls.
- might do stuff with the other ones later, but starting with just those
- get html from each url
- cache the response so i don’t keep hitting bandcamp when i fuck something up and need to run it again
- pull out the title, tags, and album/track ID using
cheerio- eventually started caching the result of this, too, it’s a somewhat expensive operation
- save as a
.jsfile that defines album data - manually copy that to cloud storage
this was fine except it required me to manually do stuff which is horrible but i convinced myself it’s good enough because i’m trying to fight against my impulse to hold things back until they are ✨perfect✨
before fixing that I needed to do something because the way consumed the firehose was melting my NAS—it couldn’t keep up with the firehose and was consistently dropping posts. it’s not a very powerful machine.
jetstream just right
figured that since i’m not generating feeds, maybe forking off feed-generator is not the optimal move. looked into the bluesky jetstream, switched over to @skyware/jetstream and it both greatly simplified things and fixed the performance issues.
seriously the whole watcher is 25 lines
import { Jetstream } from "@skyware/jetstream";
import WebSocket from "ws";
const jetstream = new Jetstream({
ws: WebSocket,
wantedCollections: ["app.bsky.feed.post"],
});
jetstream.onCreate("app.bsky.feed.post", (event) => {
const post = event.commit;
for (const facet of post.record.facets ?? []) {
for (const feature of facet.features ?? []) {
if (feature.$type !== "app.bsky.richtext.facet#link") {
continue;
}
if (feature.uri.match(/(\.bandcamp\.com\/)|(\/\/ampwall\.com\/)/)) {
console.log(JSON.stringify({ ...post, did: event.did }));
break;
}
}
}
});
jetstream.start();an iteration (ᛞ)
here’s the current web-scale version
IN=posts.jsonl
OUT=album-data.js
watcher | tee -a $IN | cleaner $IN | enricher | compiler $OUToh, and in another tmux window
op run sync-album-data album-data.jswatcher: pull music posts off the jetstream- keeping all
bandcamp.comandampwall.comlinks - can’t do anything with
ampwalllinks yet, but want them for the future
- keeping all
cleaner: filter down tobandcamp.com/(album|track), throw out most of the post data since we’re not using it for anything yet- stream
$INbefore streaming fromstdin
- stream
enricher: go off to bandcamp and pull the album/track information- throw out any unexpected results (404s, missing images or weird pages)
- caches http responses and parsing results
compiler: de-duplicates and compiles the stream down toalbum-data.jssync-album-data: copiesalbum-data.jsto my cloud storage in awhile truewith asleep 120opis the 1Password CLI, I use it for secrets injection, which i should write a whole ‘nother post about because it’s neat
breaking it up this way made things pretty easy to test different parts with both canned and live input. i’m using esbuild to create standalone bundles for each of the stages and i have a script that copies them to the NAS. eventually i’ll do something smarter, but it’s fine for now.
using stromjs makes building each stage pretty straightforward. this is the main function of cleaner:
function main() {
const streamPrefix = process.argv[2];
const cleaner = compose([
jsonl(), //see appendex
flatMap(extractMusicUris),
stringify(),
join("\n"),
]);
let stream = process.stdin as Readable;
if (prefix) {
stream = merge(createReadStream(streamPrefix), process.stdin);
}
stream.pipe(cleaner).pipe(process.stdout);
}there’s certainly a lot of serializing and deserializing going on across the whole pipeline, but that’s nowhere close to the bottleneck of this stream processor so it doesn’t matter to me.
what’s next
- add ampwall support
- it’s the second sentence of this blog post! i am capturing those posts i’m just not doing anything with them yet
- opt-in to updates without having to reload the whole page
- notify when there’s a new set of albums and add those
- better spam protection
- i dropped
dids for a while on accident, but I have them back now so i can start ❌ing folks who are doing nothing but spamming links
- i dropped
- pagination of some sort
- right now i’m just loading every fuckin thing that’s ever been observed and that party is certainly not gonna last
- thinking about different ways to do this without losing ability to search everything or having to introduce a server
- browser extension/userscript for bc/ampwall
- send
postMessages from embed so I can get around cross origin protection and know when & what things are playing, which would let me add global player controls
- send
- more performance optimizations
- it’s able to handle ~2000 albums pretty well even on slow 4G and 4x CPU throttling, but i always want to do better! been thinking about strategies for improving local caching and incremental updates to improve all loads after first
appendix: jsonl
export function jsonl(): Compose {
return compose([
split("\n"),
map((line: string) => line.trim()),
filter((str) => !!str),
parse(),
]);
}Footnotes
-
begrudgingly had to wrap each entry in a container element with
inline-blockeventually ↩ -
unfortunately broken on Firefox Mobile for Android. there’s a 6 year old bug open for it ↩